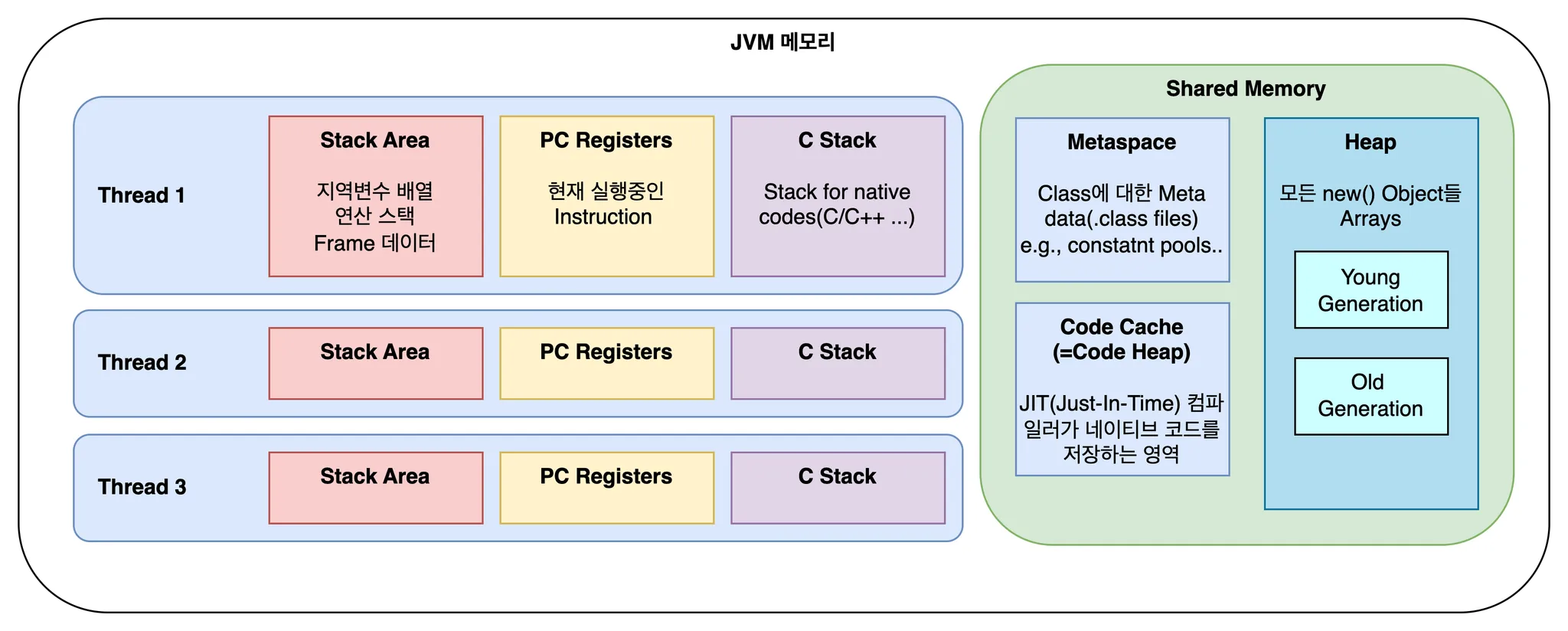
Intro
이번 Jungle CS 스터디의 주제는 “System Call”입니다. 저는 이번 개인 주제로서, JVM에서 System Call이 어떻게 동작하는지에 대해 소개해보겠습니다. 글의 개요는 아래와 같습니다.
개요
- System Call의 배경과 필요성
- System Call의 동작 원리
- JVM과 System Call
- JVM 기반 언어 vs. Native 언어(C)의 System Call 접근 방식 비교
System Call의 배경과 필요성
우리는 컴퓨터 하나에서 동시에 많은 프로그램을 사용할 수 있습니다. 이는 운영체제가 각 프로세스 별로 공정하게 하드웨어 자원을 분배하는 역할을 하기 때문이죠. 수많은 프로세스는 결국 유한한 하드웨어를 공유하며 동작하고 있는 것입니다. 그렇다면 만약 하나의 프로세스가 다른 프로세스의 허락 없이 데이터를 읽고 수정할 수 있다면 어떻게 될까요? 또는 어떤 프로세스가 모든 프로세스가 공유하는 하드웨어 자원의 사용을 못하게 망가트린다면? 심각한 데이터 유출이나 발생하거나 컴퓨터 사용에 큰 지장이 생길 것입니다.
따라서 하드웨어 자원을 추상화하고 효율적인 운영에 책임이 있는 OS는, 프로세스의 하드웨어 자원 사용을 엄격하게 제한할 필요가 있습니다. 이를 위해 OS는 최소 두가지 실행 모드를 제공합니다.
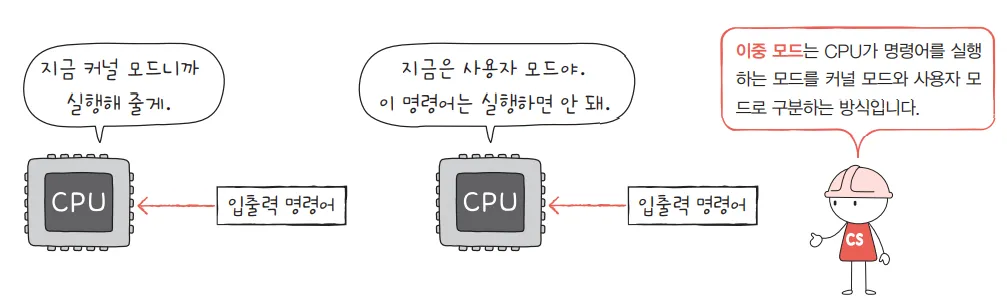
- 사용자 모드(User Mode): 제한된 명령어만 실행할 수 있으며, 하드웨어 자원에 직접 접근할 수 없습니다. 일반 애플리케이션은 이 모드에서 실행됩니다.
- 커널 모드(Kernel Mode): 모든 하드웨어 자원에 직접 접근이 가능하며, 모든 CPU 명령어 실행 권한을 가집니다. 운영체제의 핵심 부분인 커널이 이 모드에서 실행됩니다.
프로세스(User Mode)는 하드웨어 자원에 대한 접근이 필요하다면, 반드시 OS에게 하드웨어 사용을 요청해 OS가 Kernel Mode에서 하드웨어를 사용할 수 있게해야 합니다. System Call이란, 위 과정에서 프로세스가 OS에게 하드웨어 접근 사용을 허가 받기 위한 요청을 의미합니다. 조금더 자세히 System Call의 역할에 대해 알아봅시다.
System Call의 역할
System Call은 사용자 모드 프로그램과 커널 모드 운영체제 사이의 인터페이스를 제공합니다. 이는 다음과 같은 역할을 수행합니다:
- 보호 경계(Protection Boundary) 유지: 사용자 프로그램이 운영체제나 다른 프로그램의 중요한 부분에 직접 접근하는 것을 방지합니다.
- 제어된 인터페이스 제공: 애플리케이션이 하드웨어와 시스템 자원에 접근할 수 있는 안전하고 일관된 방법을 제공합니다.
- 권한 검증(Privilege Checking): 요청된 작업을 수행할 권한이 있는지 확인하여 보안을 강화합니다.
- 추상화 계층(Abstraction Layer) 제공: 하드웨어의 복잡성을 감추고 일관된 API를 제공하여 애플리케이션 개발을 단순화합니다.
System Call을 어렵게 생각할건 없습니다. 우리는 이미 밥먹듯이 System Call을 쓰고 있거든요. 파일을 읽고 실행하고 종료하는 것도 System Call 없이는 불가능합니다. print() 문을 사용하거나, scanner로 사용자 입력을 받는 것도 System Call이 필요하지요. 이렇게 핵심적인 역할을 하는 System Call은 그렇다면 어떻게 동작하는 걸까요?
System Call의 동작 원리
System Call의 핵심은 사용자 모드(User Mode)에서 커널 모드(Kernel Mode)로의 안전한 전환입니다. 이 전환 과정은 일종의 '문지기'가 있는 출입문을 통과하는 것과 비슷합니다. 프로그램은 마음대로 커널 영역에 들어갈 수 없고, 반드시 정해진 절차와 방법을 통해서만 접근이 가능합니다.
트랩(Trap) 메커니즘과 인터럽트 처리
System Call이 작동하는 핵심 메커니즘은 '트랩(Trap)'이라고 불리는 특별한 형태의 인터럽트입니다. 인터럽트란 CPU에게 "잠깐만, 지금 하던 일을 멈추고 이것을 처리해야 해!"라고 알리는 신호입니다.
Interrupt에는 크게 두 종류가 있습니다:
(정확히는, interrupt, trap, exception, fault, and abort 등의 단어는 명확한 정의는 없다고 합니다)
- Hardware Interrupt
- 디스크, 키보드, 네트워크 카드, DMA 등의 장치가 발생
- Software Interrupt
- Exception(예외)
- 0으로 나누기, 접근 권한 위반 등 프로그램 실행 중 오류가 발생할 때 생성
- Trap(트랩)
- 프로그램이 의도적으로 발생시키는 인터럽트로, System Call이 여기에 해당합니다.
- Exception(예외)
트랩은 특별한 명령어(int, syscall, svc 등 아키텍처마다 다름)를 통해 의도적으로 발생시키는 인터럽트입니다. 이 명령어가 실행되면 다음과 같은 일이 발생합니다:
- CPU는 현재 실행 중인 프로그램의 상태(레지스터 값, 프로그램 카운터 등)를 저장합니다.
- CPU 모드가 사용자 모드에서 커널 모드로 전환됩니다.
- 제어권이 커널의 인터럽트 핸들러로 넘어갑니다.
이것은 마치 비행기를 타기 위해 보안 검색대를 통과하는 것과 비슷합니다. 여러분의 신원(프로그램 상태)이 확인되고, 제한 구역(커널 모드)으로 들어갈 수 있는 허가를 받는 과정입니다.
유저 모드에서 커널 모드로의 전환 과정
System Call의 전체 과정을 단계별로 살펴보겠습니다:
- 애플리케이션 요청: 프로그램이 System Call 라이브러리 함수를 호출합니다. 예를 들어 C 프로그램에서 printf()를 호출하면, 이는 내부적으로 write() System Call을 사용합니다.
- 라이브러리 래퍼(Wrapper): 라이브러리 함수는 필요한 매개변수를 준비하고, CPU 레지스터에 System Call 번호와 매개변수를 설정합니다.
- 트랩 명령어 실행: syscall(x86-64), svc(ARM) 등의 특별한 명령어를 실행하여 트랩을 발생시킵니다.
- 모드 전환: CPU가 사용자 모드에서 커널 모드로 전환됩니다. 이때 중요한 점은 프로그램의 실행 흐름이 바뀐다는 것입니다. 프로그램의 다음 명령어가 아닌, 커널의 System Call 핸들러로 점프합니다.
- System Call 핸들러: 커널은 요청된 System Call 번호를 확인하고, 해당하는 커널 함수를 호출합니다.
- 권한 검사: 커널은 프로세스가 요청한 작업을 수행할 권한이 있는지 확인합니다. 예를 들어, 파일을 열려면 해당 파일에 대한 접근 권한이 있어야 합니다.
- 요청 처리: 권한 검사를 통과하면, 커널은 요청된 작업(파일 읽기, 네트워크 패킷 전송 등)을 수행합니다.
- 결과 준비: 작업이 완료되면 결과 값(성공/실패 코드, 읽은 데이터 등)을 사용자 프로그램에 반환할 준비를 합니다.
- 사용자 모드 복귀: 커널은 다시 사용자 모드로 전환하고, 제어권을 System Call을 호출한 프로그램의 다음 명령어로 돌려줍니다. 결과 값은 보통 레지스터를 통해 전달됩니다.

쉽게 얘기해서 음식점에서 손님이 칵테일을 주문하는 것과 비슷합니다. 손님(process)가 직원(OS)를 불러서, 먹고 싶은 칵테일의 번호(Trap No.)를 불러주며 주문합니다(System Call). 그럼 직원은 손님이 성인인지 확인하고(권한검사), 바 테이블로 가서(커널모드 전환) 칵테일을 제조하죠(커널이 작업 수행). 그리고 칵테일이 완성되면 바를 나가(사용자 모드 복귀), 손님에게 주문한 칵테일을 대접하는거죠!
컨텍스트 스위칭의 비용
우리는 칵테일을 한 잔씩 주문할 때마다 직원에게 돈을 내야해죠. 그것처럼 System Call을 통해 User Mode → Kernel Mode로 전환(Context Swiching) 하는데에도 비용이 필요합니다. 이러한 비용을 Context Swiching Cost라고 하죠.
- CPU 상태 저장: 현재 실행 중인 프로그램의 상태(레지스터 값, 프로그램 카운터 등)를 저장해야 합니다.
- CPU 캐시 영향: 모드가 전환되면 CPU 캐시의 효율성이 떨어질 수 있습니다. 커널 코드와 데이터가 캐시를 차지하게 되어, 사용자 프로그램의 캐시 데이터가 밀려날 수 있습니다.
- TLB(Translation Lookaside Buffer) 플러시: 일부 아키텍처에서는 모드 전환 시 TLB를 플러시(비우기)해야 하며, 이는 메모리 접근 성능을 일시적으로 저하시킵니다.
- 파이프라인 비우기: 현대 CPU의 명령어 파이프라인이 비워져야 할 수도 있습니다.
일반적인 함수 호출은 몇 나노초 정도 소요되는 반면, System Call은 수백 나노초에서 마이크로초 단위의 시간이 걸릴 수 있습니다. 이는 100~1000배 더 느릴 수 있다는 의미입니다!
이런 비용 때문에, 성능이 중요한 애플리케이션에서는 System Call의 사용을 최소화하는 기법을 사용합니다.
- 버퍼링(Buffering): 작은 데이터를 여러 번 쓰는 대신, 큰 버퍼에 모았다가 한 번에 쓰는 방식을 사용합니다. 이는 write() System Call의 호출 횟수를 줄여줍니다.
- 메모리 매핑(Memory Mapping): mmap() System Call을 사용하여 파일을 메모리에 매핑하면, 이후 파일 접근이 일반 메모리 접근으로 처리되어 추가적인 System Call이 필요 없게 됩니다.
- 배치 처리(Batching): 최신 Linux 커널의 io_uring과 같은 인터페이스는 여러 I/O 작업을 한 번의 System Call로 처리할 수 있게 해줍니다.
휴 System Call 개념을 설명하는 것만 해도 힘이 드네요. 드디어 본론인 JVM에서 System Call은 어떤 과정으로 동작하는지에 대해 알아봅시다.
JVM과 System Call
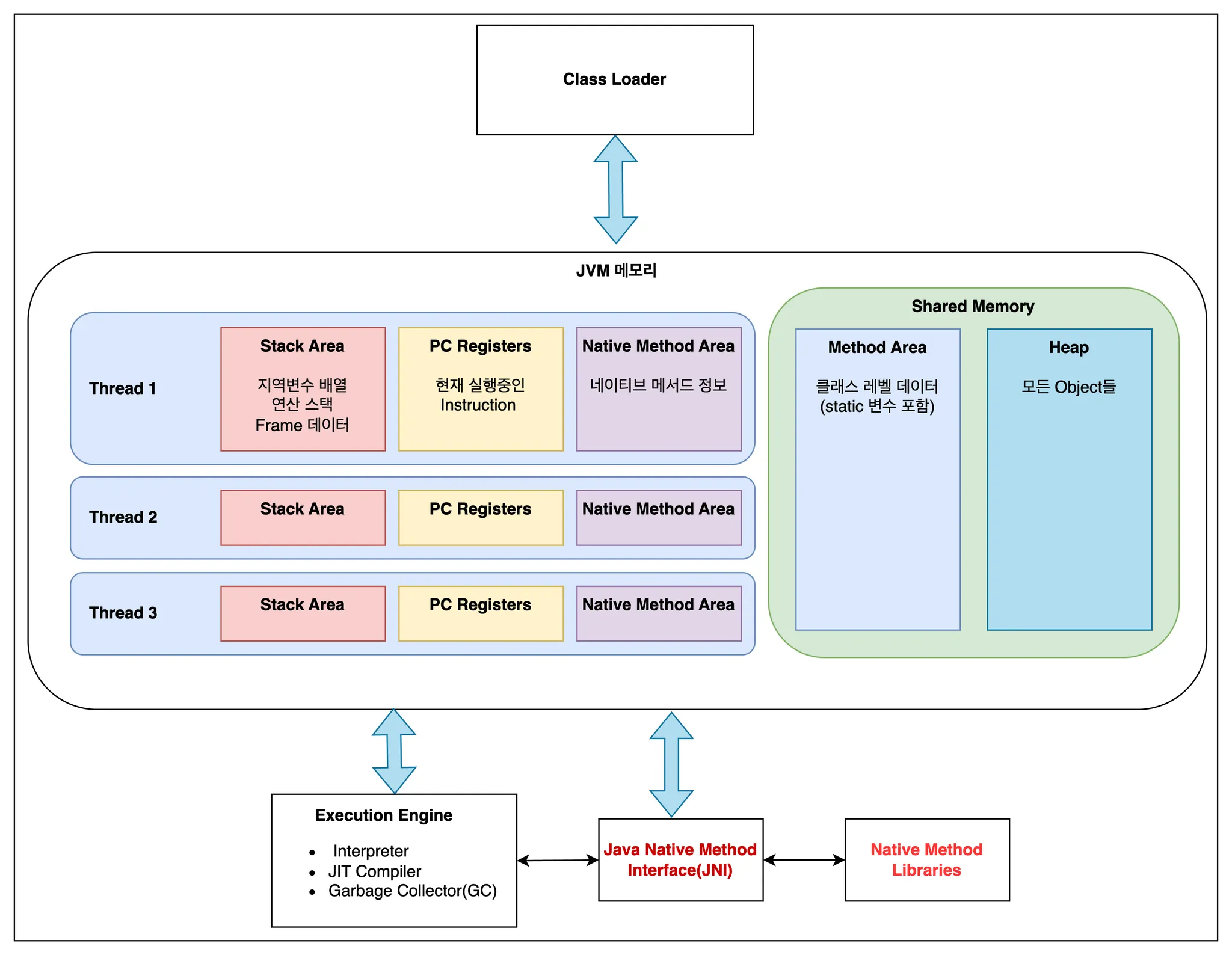
저번 게시물에도 언급했듯이, 자바의 철학은 “Write Once, Run Anywhere”입니다. 이러한 철학에 대한 구현이 바로 java와 운영체제 사이에 존재하는 JVM(Java Virtual Machine)이구요. 저번에는 JVM의 메모리 구조에 집중했습니다. 이번 주제인 System Call이 JVM에서 사용되는 과정을 이해하기 위해선 JVM의 전체 구조 중, Java Native Method Interface(JNI)와 Native Method Libraries를 집중해서 보겠습니다.
Native Method
먼저, Native Method란 무엇일까요? Java에서 네이티브 메소드란, Java가 아닌 다른 언어(주로 C/C++)로 작성된 메소드로써, native keyword로 선언된 메소드를 의미합니다. Java 자체만으로는 접근하기 어려운 하드웨어 자원 제어, 운영체제 특정 기능 활용, 또는 성능상의 이유로 다른 언어로 구현된 기능 등이 있죠. 이 메소드들은 native 키워드로 선언되며, 실제 구현은 Native Method Libraries에 있습니다.
public class FileExample {
// 네이티브 메소드 선언
private native int open(String path, int flags);
private native int write(int fd, byte[] buffer, int size);
private native int close(int fd);
// 네이티브 라이브러리 로드
static {
System.loadLibrary("fileio");
}
// Java 메소드에서 네이티브 메소드 호출
public void writeToFile(String path, String content) {
int fd = open(path, 1); // 1은 쓰기 모드를 의미
byte[] data = content.getBytes();
write(fd, data, data.length);
close(fd);
}
}
이 예제에서 open(), write(), close()는 Native Method로, 실제 구현은 'fileio'라는 네이티브 라이브러리에 있습니다. 그리고 Native Method에 대한 구현이 바로 Native Method Libraries에 있는 Native Code인 것이죠. 즉 요약하자면,
- Native Method: Java 코드 내에 선언된 인터페이스이며, 실제 동작은 Native Code에 위임합니다.
- Native Code: JVM 외부에서 실행되는 실제 구현체이며, 운영체제와 직접 상호작용하여 Native Method가 요청한 작업을 수행합니다. System Call이 실행되죠(System Call이 필요할 때만)
즉 Java에서 System Call은 Native Method를 통해 Native Code가 실행되며 실행되는 것입니다. 그리고 이를 가능케 하는 중간자로 JNI(Java Native Method Interface)가 있습니다.
Java Native Method Interface(JNI)의 역할
JNI(Java Native Method Interface)는 Java 코드와 네이티브 코드(C, C++ 등) 간의 다리 역할을 하는 인터페이스입니다. JNI를 통해 Java는:
- Native Method를 호출할 수 있습니다.
- Java 객체를 네이티브 코드에 전달할 수 있습니다.
- Native Code에서 Java 객체의 필드를 읽고 쓸 수 있습니다.
- Native Code에서 Java 메소드를 호출할 수 있습니다.
JNI는 Java의 플랫폼 독립성을 해치지 않으면서도 운영체제의 네이티브 기능을 활용할 수 있게 해주는 중요한 메커니즘입니다. JNI는 통역사와 비슷한 역할을 하는거라 할 수 있죠. 서로 다른 언어를 쓰는 외국인들끼리 만나도, 통역사를 통해 의사소통이 가능한 거죠.
JNI를 사용하는 네이티브 코드의 예를 살펴보겠습니다:
#include <jni.h>
#include <fcntl.h>
#include <unistd.h>
// Java_클래스명_메소드명 형식으로 함수 이름 지정
JNIEXPORT jint JNICALL Java_FileExample_open
(JNIEnv *env, jobject obj, jstring path, jint flags) {
// Java 문자열을 C 문자열로 변환
const char *nativePath = (*env)->GetStringUTFChars(env, path, NULL);
// open() 시스템 콜 호출
int fd = open(nativePath, flags);
// 자원 해제
(*env)->ReleaseStringUTFChars(env, path, nativePath);
return fd;
}
// write(), close() 메소드도 비슷한 방식으로 구현
이 C 코드는 Java의 네이티브 메소드에 대응하는 네이티브 구현입니다. 여기서 open() 함수는 운영체제의 System Call을 직접 호출합니다.
자 이제 JVM 내부에서 System Call이 호출되는 과정을 이해하기 위한 개념 정리는 다 했습니다. 전체 과정을 살펴봅시다.
JVM 내부의 System Call 호출 과정
Java 프로그램에서 System Call이 호출되는 전체 과정을 살펴보겠습니다:
- Java 코드 실행: Java 애플리케이션이 표준 라이브러리 메소드(예: FileOutputStream.write())를 호출합니다.
- Java API 처리: 표준 라이브러리는 이 호출을 처리하고, 필요한 경우 JVM의 네이티브 메소드를 호출합니다.
- 네이티브 메소드 호출: JVM은 JNI를 통해 네이티브 라이브러리의 함수를 호출합니다.
- System Call 호출: 네이티브 함수는 운영체제의 System Call을 호출합니다.(By native code, …)
- 커널 처리: 커널은 System Call을 처리하고 결과를 반환합니다.
- 결과 전달: 결과가 네이티브 함수 → JVM → Java API → Java 애플리케이션으로 전달됩니다.
개념들을 알고나니 실행 과정을 이해하는게 어렵지 않죠? 그렇다면 System Call을 사용하는 Java Standard Libraries의 기능 예시를 몇가지만 살펴봅시다.
Java 표준 라이브러리와 System Call 매핑
Java 표준 라이브러리의 많은 기능들은 내부적으로 System Call에 의존합니다. 주요 예를 살펴보겠습니다:
파일 입출력
FileOutputStream fos = new FileOutputStream("test.txt");
fos.write("Hello, World!".getBytes());
fos.close();
사용 System Calls:
- open(): 파일 생성/열기
- write(): 데이터 쓰기
- close(): 파일 닫기
네트워크 통신
Socket socket = new Socket("example.com", 80);
OutputStream out = socket.getOutputStream();
out.write("GET / HTTP/1.1\\r\\n\\r\\n".getBytes());
사용 System Calls:
- socket(): 소켓 생성
- connect(): 서버에 연결
- write(): 데이터 전송
스레드 관리
Thread thread = new Thread(() -> {
System.out.println("Hello from thread!");
});
thread.start();
사용 System Calls:
- clone() 또는 pthread_create(): 새 스레드 생성
- futex(): 스레드 동기화 (Linux의 경우)
이 외에도, 하드웨어 자원 사용이나 실행 흐름과 관련된 기능 등 매우 많은 기능들이 System Call을 사용합니다. System Call에 대한 이해 없이 언어의 동작 과정을 이해하는 건 불가능에 가깝죠. 하지만 Java는 System Call을 몰라도 편하게 사용할 수 있게 잘 추상화시켜놨습니다.
Java의 System Call 추상화 계층
Java는 운영체제의 System Call을 직접 노출하는 대신, 여러 계층의 추상화를 통해 이를 감춥니다:
- 고수준 API: Files, Paths, Channels 등의 현대적인 API
- 중간 수준 API: InputStream, OutputStream 등의 전통적인 API
- 저수준 JVM 네이티브 메소드: 내부 구현에 사용되는 메소드
- 운영체제별 네이티브 라이브러리: 각 OS에 맞는 구현
- 운영체제 System Call: 실제 커널 기능
이러한 계층 구조 덕분에 Java 개발자는 운영체제의 차이점을 신경 쓰지 않고도 코드를 작성할 수 있습니다. 같은 Java 코드가 Windows, Linux, macOS에서 동일하게 동작하는 것은 JVM이 각 운영체제에 맞는 네이티브 코드와 System Call을 알아서 처리해주기 때문입니다
JVM 기반 언어 vs. Native 언어(C)의 System Call 접근 방식 비교
JVM 기반 언어(Java, Kotlin, Scala …)는 패키지 여행과 같아 현지 언어와 문화(OS)를 몰라도 가이드가 모든 것을 처리해주죠. 반면 Native 언어는 가이드 없이 가는 자유여행이라 더 자유롭고 내 마음대로 여행할 수 있지만, 현지 언어와 문화(OS)에 맞게 개인이 일일이 준비를 해야합니다. 두 진영의 System Call에 대한 접근 방식도 이러한 차이에서 비롯합니다.
크로스 플랫폼 지원
플랫폼 이식성은 두 접근 방식의 가장 큰 차이점 중 하나입니다:
- 네이티브 언어:
- 각 운영체제별로 소스 코드를 수정하거나 조건부 컴파일이 필요합니다.
- 각 플랫폼별로 다시 컴파일해야 합니다.
- System Call의 차이를 개발자가 직접 처리해야 합니다.
#ifdef _WIN32 // Windows 시스템 콜 사용 HANDLE file = CreateFile("test.txt", GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); WriteFile(file, "Hello, World!", 13, &bytesWritten, NULL); CloseHandle(file); #else // UNIX/Linux 시스템 콜 사용 int fd = open("test.txt", O_WRONLY | O_CREAT, 0644); write(fd, "Hello, World!", 13); close(fd); #end - JVM 기반 언어:
- "Write Once, Run Anywhere" - 한 번 작성하면 어디서나 실행 가능합니다.
- JVM이 각 플랫폼의 차이를 추상화합니다.
- 개발자는 운영체제 차이를 거의 신경 쓰지 않아도 됩니다.
// 어떤 운영체제에서도 동일하게 작동 FileOutputStream fos = new FileOutputStream("test.txt"); fos.write("Hello, World!".getBytes()); fos.close();
이는 마치 네이티브 언어는 각 나라의 현지 언어로 대화해야 하는 것과 같고, JVM 언어는 어디서나 영어로 대화할 수 있는 것과 비슷합니다.
플랫폼 특화 기능 접근성
반면, 각 플랫폼의 고유 기능을 활용하는 측면에서는:
- 네이티브 언어:
- 운영체제의 모든 특화 기능에 쉽게 접근할 수 있습니다.
- 최신 System Call이나 API를 즉시 활용할 수 있습니다.
- JVM 기반 언어:
- 플랫폼 특화 기능은 JNI를 통해 접근해야 합니다.
- JVM이 새로운 System Call을 지원하기까지 시간이 걸릴 수 있습니다.
- 일부 저수준 기능은 표준 API로 제공되지 않을 수 있습니다.
따라서 특정 운영체제의 고유 기능이 필요한 애플리케이션(예: 시스템 드라이버, 저수준 도구)은 네이티브 언어가 유리하고, 다양한 플랫폼에서 일관되게 동작해야 하는 애플리케이션(예: 엔터프라이즈 소프트웨어, 웹 애플리케이션)은 JVM 기반 언어가 유리합니다.
오버헤드의 차이
두 접근 방식의 가장 큰 차이점 중 하나는 성능 오버헤드입니다:
- 네이티브 언어: System Call로의 전환만 오버헤드로 발생합니다. 즉, 사용자 모드 → 커널 모드 전환 비용만 지불합니다.
- JVM 기반 언어: JVM 추상화, JNI 변환, 그리고 사용자 모드 → 커널 모드 전환 등 여러 단계의 오버헤드가 발생합니다.
실제 벤치마크에 따르면, 단순한 System Call(예: 파일 열기/닫기)의 경우 JVM 언어는 네이티브 언어보다 2~10배 더 느릴 수 있습니다. 그러나 이 차이는 아래와 같은 상황에서 줄어듭니다:
- 실제 작업(I/O, 연산 등)이 오래 걸리는 경우
- JIT 컴파일러가 코드를 최적화한 경우
- 반복적인 호출로 JVM이 최적화 기회를 얻은 경우
이는 마치 택시와 버스의 차이와 비슷합니다. 짧은 거리에서는 택시(네이티브)가 훨씬 빠르지만, 장거리에서는 고속버스(JVM)도 비슷한 시간이 걸릴 수 있습니다.
메모리 사용과 가비지 컬렉션
System Call 성능에 영향을 미치는 또 다른 중요한 요소는 메모리 관리 방식입니다:
- 네이티브 언어:
- 명시적인 메모리 관리(malloc/free)로 인해 개발자가 완전히 제어할 수 있습니다.
- 가비지 컬렉션으로 인한 지연이 없습니다.
- 그러나 메모리 누수나 버퍼 오버플로우 위험이 있습니다.
- JVM 기반 언어:
- 가비지 컬렉션이 자동으로 메모리를 관리합니다.
- 가비지 컬렉션 중 일시적인 지연(Stop-the-World)이 발생할 수 있습니다.
- 메모리 안전성이 더 높지만, 세밀한 제어는 어렵습니다.
System Call이 많은 애플리케이션에서는 가비지 컬렉션으로 인한 지연이 실시간 성능에 영향을 줄 수 있습니다. 이는 마치 고속도로에서 주행 중에 갑자기 연료(메모리)를 채우기 위해 정차하는 것과 비슷합니다.
결론: 각자의 장단점
JVM 기반 언어와 네이티브 언어의 System Call 접근 방식은 각각 고유한 장단점을 가지고 있습니다:
네이티브 언어의 강점:
- System Call에 대한 직접적이고 효율적인 접근
- 더 적은 런타임 오버헤드와 메모리 사용량
- 운영체제와 하드웨어의 모든 기능에 완전한 접근
JVM 기반 언어의 강점:
- 뛰어난 플랫폼 이식성과 "Write Once, Run Anywhere" 특성
- 자동화된 메모리 관리와 향상된 안전성
- 높은 수준의 추상화와 개발자 생산성
어떤 접근 방식이 "더 좋다"고 단정할 수는 없으며, 기술적으로 해결해야 하는 비즈니스 문제에 따라 적절한 진영을 선택하면 되겠습니다.
후기
후… 글 정리하는데 정말 힘들었습니다. 특히 적절한 비유를 생각해내는게 쉽지 않았는데 CS 개념을 나만의 비유를 만들어 설명하는 방식이 개념을 이해하는데 크게 도움이 되는 것 같았습니다.
또한 java는 언어와 운영체제 사이의 JVM 위에서 동작하지만, 결국 밑으로 들어가면 OS에서 배운 것과 똑같이 Native하게 동작한다는 것을 다시한번 느꼈습니다. 결국 OS 지식 없이는 언어의 동작 원리 무엇하나 이해할 수 없는 것이지요… Krafton Jungle에서 CS 중심의 학습을 하지 않았다면 이런 글을 도저히 적지 못했을 겁니다. 그리고 이번 Jungle CS Study를 통해 복습할 수 있어서 너무 좋네요. 추가로 공부해보고 싶은 내용도 마구마구 생각나구요! 다음 주제는 다른 스터디원 분들이 원하는 것으로 하기로 해 무엇이 될지 모르겠지만, 어떻게라도 자바와 엮어 준비해보겠습니다! 기다려주세용
출처
https://product.kyobobook.co.kr/detail/S000001868716
https://m.yes24.com/Goods/Detail/93738334
https://product.kyobobook.co.kr/detail/S000001550352
https://brewagebear.github.io/java-syscall-and-io/
https://inpa.tistory.com/entry/JAVA-☕-JVM-내부-구조-메모리-영역-심화편?category=976278
https://hongong.hanbit.co.kr/운영체제란-커널의-개념-응용-프로그램-실행을-위한/
'JAVA' 카테고리의 다른 글
| Process Memory 구조와 JVM의 Memory 구조 (1) | 2025.04.22 |
|---|